Lọc trùng dữ liệu
Ý chính
- Sử dụng Bash với công cụ
cat,parallel,sed,sortcho kết quả tối ưu nhất.
Giới thiệu
Khi làm việc với dữ liệu thô, theo trạng thái từng từ, mỗi từ một dòng (thường dùng trong làm từ điển), dữ liệu thường bị thừa ra. Nguyên nhân là do dữ liệu trùng nhau, các kí tự thừa (\r, \n, space) ở đầu và cuối các từ làm bộ lọc nhầm lẫn cho rằng đây là các từ khác nhau. Vậy nên bài toán đặt ra trong quá trình làm sạch dữ liệu là xóa các kí tự thừa ở đầu và cuối của từ, sắp xếp và lọc các từ trùng nhau.
Trong làm việc với dữ liệu ít, công việc đó đơn giản, thậm chí làm việc với các phần mềm bảng tính như Excel cũng có thể giải quyết vấn đề. Tuy nhiên, với dữ liệu bắt đầu từ 100 Mb đến hàng GB, TB thì ta phải có một số thủ thuật. Trong bài viết này mình sẽ chia sẻ kinh nghiệm vài lần xử lý và số liệu benchmark.
Thử nghiệm lọc trùng lần thứ nhất
Điều kiện
Máy tính cá nhân với cấu hình:
- OS: Ubuntu 14.04
- RAM: 4GB
- CPU: Intel® Core™ i5-2430M CPU @ 2.40GHz × 4
Dữ liệu được phân bổ:
1k.txt: 1,000 dòng đầu tiên của tệp dữ liệu.100k.txt: 100,000 dòng đầu tiên của tệp dữ liệu gốc.6tr.txt: Tệp dữ liệu gốc chứa khoảng 6 triệu dòng.
Phương thức thực hiện
Mình sẽ sử dụng 3 ngôn ngữ để tiện so sánh: Bash, R, và Python.
Theo những cách trước đây, sẽ sử dụng ngôn ngữ Bash và hàm có sẵn của hệ điều hành linux là sort và uniq.
cat <input-file> | sort | uniq <output-file>
Sau khi lọc trùng sẽ thu được output đã sắp xếp. Vì lệnh uniq chỉ được thực hiện sau khi đã sắp xếp input nên bắt buộc phải sort trước khi lọc trùng.
Sau một thời gian tiếp cận, mình biết thêm ngôn ngữ R được đánh giá rất tốt dùng cho Thống kê. Vậy nên mình đã cài đặt và thử nghiệm trong công việc lọc trùng. Đối với R, sau khi nhập dữ liệu, ta không cần phải sắp xếp.
Cuối cùng với ngôn ngữ Python, dùng thư viện collections.Counter để đưa dữ liệu vào bộ đếm. Sau đó ghi ra file.
Kết quả
| Ngôn ngữ | Có sắp xếp | Đầu vào | Thời gian |
|---|---|---|---|
| Bash | Có | 1k.txt | 0s |
| Bash | Có | 100k.txt | 1s |
| Bash | Có | 6tr.txt | 48s |
| R | Không | 1k.txt | 0.01s |
| R | Không | 100k.txt | 0.657s |
| R | Không | 6tr.txt | 71.624s |
| Python | Không | 1k.txt | 0.001s |
| Python | Không | 100k.txt | 0.075s |
| Python | Không | 6tr.txt | 5.926s |
Nhận xét
Như vậy, dùng Bash xử lý file 72MB sẽ phải mất thời gian khoảng 48s để thực hiện, đối với R thì mất 71s (trong đó 28s để đọc dữ liệu). Riêng đối với Python chỉ mất khoảng 6s cho tất cả các công đoạn.
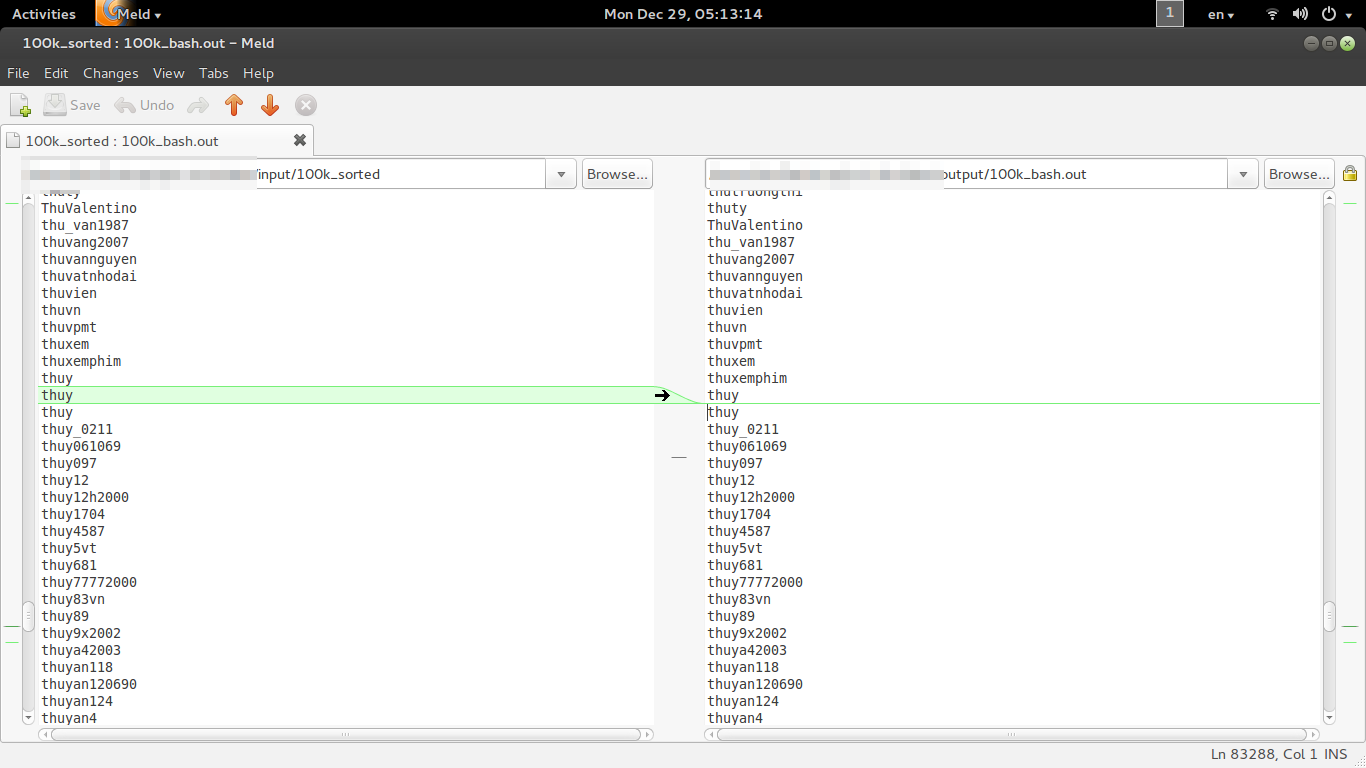
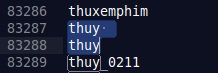
Tuy nhiên với đầu ra của dữ liệu thì chênh lệch nhau khá lớn giữa các ngôn ngữ. Sau khi kiểm tra các file đầu ra của bộ input 100k, không tìm thấy sự khác nhau của output giữa các ngôn ngữ. Tuy nhiên lại có một phát hiện khác khi sử dụng lệnh cat -v đối với file 1k-python.out, cuối mỗi dòng xuất hiện ký tự ^M (\r trong Windows).
Hơn nữa, sau khi xem kĩ các file output, nhận thấy các kí tự thừa khoảng trống đằng sau nhưng vẫn không bị lọc.
Rút kinh nghiệm
- Với khả năng tối ưu nhất, mình sẽ sử dụng Python để thực hiện các lần thử nghiệm tiếp theo.
- Tiền xử lý dữ liệu (pre-process) bằng cách xoá hết các khoảng trống trước và sau của mỗi dòng.
- Sử dụng đa luồng (multi-thread) để tăng tốc độ xử lý của CPU.
Thử nghiệm lần hai
Điều kiện
- Tương tự như điều kiện của lần 1.
- Thêm file
full.txtchứa toàn bộ dữ liệu cần xử lý (khoảng 500 MB).
Phương thức thực hiện
Trước hết, xoá hết các ký tự khoảng trống, \n, \r ở trước và sau mỗi dòng.
Sử dụng hàm map(str.strip, data) của Python sau khi đọc file để thực hiện tác vụ trên. Các bước thử nghiệm tương tự lần trước.
Kết quả
| File | Đọc | Xử lý | Ghi | Tổng |
|---|---|---|---|---|
| 1k.txt | 0.000s | 0.000s | 0.000s | 0.001s |
| 100k.txt | 0.004s | 0.052s | 0.047s | 0.103s |
| 6tr.txt | 0.261s | 3.740s | 2.594s | 6.595s |
| full.txt | 1m 6s | 9m 18s | 34m 19s | 44m 44s |
Nhận xét
- Với 2 file
1k.txtvà100k.txt, khi chưa có sự trùng lặp nhiều về các từ chứa kí tự trống 2 đầu, dung lượng file tương đồng với cách sử dụng Bash. Có thể kết luận mỗi dòng chứa thêm kí tự^Mđã làm dung lượng file tăng lên đáng kể. - Đối với output của tập đầu vào
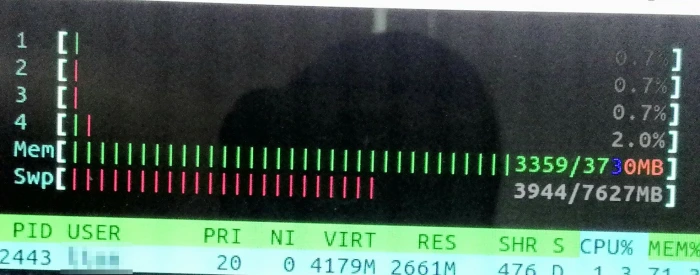
6tr.txt, dung lượng đã giảm so với tập Bash ban đầu khoảng 30 KB. - Khi xử lý với bộ dữ liệu nặng hơn, RAM bị quá tải. Khi đọc file, mặc dù số lượng biến ít, nhưng giá trị của biến sẽ phải nạp tương ứng với kích thước file đọc vào (trong trường hợp
full.txtlà 499 MB). Nếu như chạy toàn bộ sẽ hết dung lượng RAM và thời gian chạy sẽ rất lâu do phải đợi bộ nhớ giải phóng. Các lệnh chạy này xử lý trên RAM, không ảnh hưởng tới CPU nên việc multi-thread không cấp bách bằng việc chia nhỏ file để load. Dung lượng RAM còn lại (khi chạy song song các chương trình khác) cũng rất quan trọng. Đối với bộ dữ liệu6tr.txt, khi chạy cùng Google Chrome xảy ra tình trạng xử lý lâu, mất tới 60s thay vì 6s như trong trường hợp chạy chỉ cùng các trình editor đơn thuần.
Rút kinh nghiệm
- Cắt nhỏ file ra thành từng phần nhỏ để xử lý.
Thử nghiệm lần ba
Điều kiện
- Cấu hình và dữ liệu tương tự lần 1.
Phương thức thực hiện
Mình chưa tìm ra cách tối ưu khi load file và xử lý trên Python, vì vậy sẽ thử nghiệm với Bash để tìm cách cải tiến.
Trước đây, dòng lệnh để xử lý dữ liệu là cat <input-file> | sort | uniq <output-file>. Khi sử dụng lênh trên phát sinh một số vấn đề:
- Dùng 3 hàm liền nhau, lặp lại công việc bị thừa.
- Chưa xử lý được vấn đề có các ký tự thừa ở đầu và cuối dòng.
- Chạy đơn luồng, không tận dụng được CPU.
Mình đã khắc phục như sau:
- Dùng
sedđể xoá các ký tự không mong muốn. - Dùng
sortvới tham số -us (-u: unique, -s: stable). Khi sử dụng hai tham số này, ta đã có thể tối ưu việc xoá bỏ các dòng trùng nhau, sắp xếp, đọc file và chạy song song.

Bước 1: Tiền xử lý xoá khoảng trống
Với hàm sed, không có tham số tối ưu khi lọc dữ liệu nên chỉ chạy 1 luồng. Ta được kết quả:
| File | Thời gian |
|---|---|
| 6tr.txt | 7s |
| full.txt | 1m 29s |
Để tối ưu hơn, mình sử dụng công cụ GNU parallel để sed data. Câu lệnh tiền xử lý xoá khoảng trắng sẽ trở thành:
cat <input> | parallel –pipe sed ‘-e “s/\r//g” -e “s/^ *//” -e “s/ *$//”’ > <output>
Kết quả thu được:
| File | Thời gian |
|---|---|
| 6tr.txt | 6s |
| full.txt | 41s |
Bước 2: Sắp xếp và lọc trùng
Mình sẽ chỉ sử dụng lệnh sort với tham số -us để sắp xếp và lọc trùng. Câu lệnh sẽ trở thành:
sort -us -o <output> <input>
Thời gian thực hiện:
| File | Thời gian |
|---|---|
| 6tr.txt | 33s |
| full.txt | 3m 41s |
Nhận xét
Việc tối ưu đã hoàn thiện hơn nhiều so với lần trước.